The need for a more semantic web
The web has come a long way. From the early static pages, through the evolution of reactivity, and towards the biggest knowledge pool for all of humanity.
A little history of the web
The World Wide Web (WWW), which is commonly known as the Web, was invented by Tim Berners-Lee at CERN in 1989. It’s an information system that enabled documents and other web resources such as—images, videos, music, etc—to be accessed over the internet.
I, myself, being an early user of the web, saw it transform through different generations and paradigms. I like to call them Web 1.0, Web 2.0 and Web 3.0. Let’s explore the unique characteristics of each of those eras.
Web 1.0
When I talk about Web 1.0, I refer to the early state of the Web. The state where there was practically no standard and no interactivity. Web pages, back then, used to be completely static and written entirely in HTML (which was poorly defined as a standard back then). CSS was non-existent (it was created later, in 1996). JavaScript, which appeared in 1995, was also unheard of.
This was the era of the static, generic looking, web. This is how the first ever website looked like.
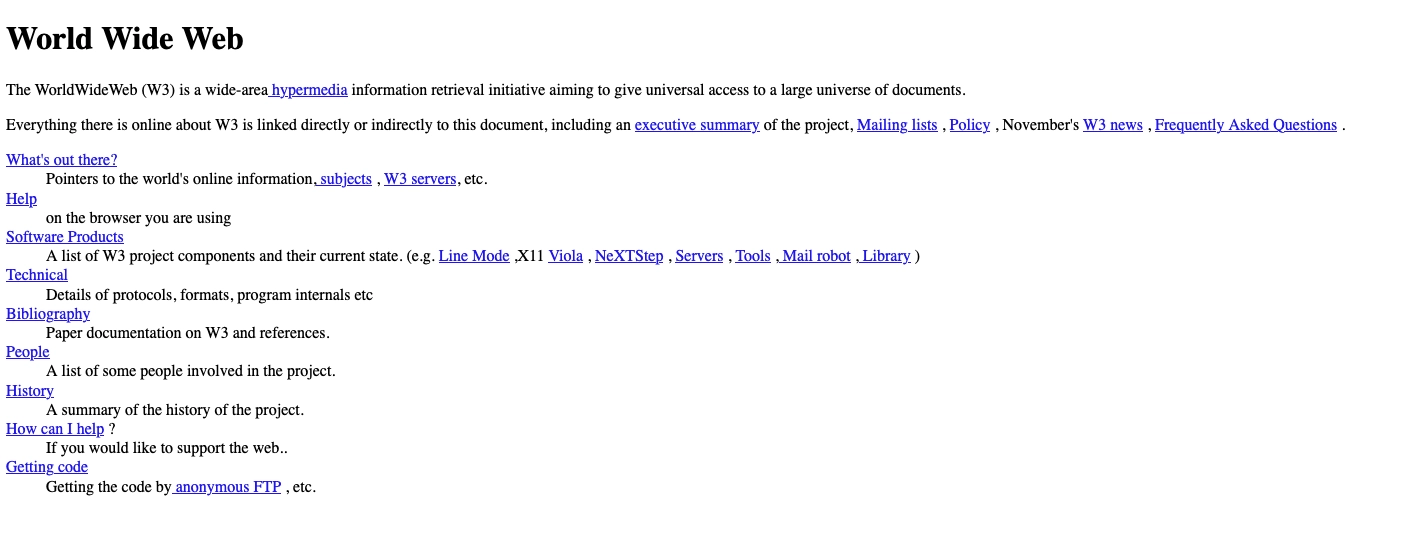
Go on, check the source of it.
Web 2.0
With the birth of CSS and JavaScript, the world entered a new era of the Web. The Web 2.0. This web provided more colors. This web provided interactivity.
Suddenly, people started to care about separation between structure (the HTML side) and appearance (the CSS side). HTML elements such as <font>, <marquee>, and <strong>—became deprecated, and were replaced with their CSS and JS counterparts.
The Web 2.0 also saw the birth of the famous XMLHttpRequest and the Ajax technology. You could replace an entire webpage, or parts of it, without navigating away from the page—which created a feeling of what today is known as SPA—Single page application.
On the HTML side, we saw the appearance of some semantic attributes such as <article>, <section>, <aside>, and others. Finally, in 2008, HTML5 was released, which among many things, added a support for Microdata. Remember this, as we will talk about Microdata later.
With the rise of the Web 2.0, came the rise in content published in the World Wide Web. Suddenly it became easier, cheaper, and more accessible to have a web page. People, and companies, started to care about web presence. And more over—the Web became a place of knowledge. This era gave birth to concepts such as blogging and forums. In 2001—Wikipedia was born. And as the amount of content grew, the need to find content became a necessity. In 1998 Google was created, and later became the dominant search engine till this day.
Web 2.0 was a great era. An era of revolution in the way we present our webpages, as well as revolution in the way the Web is being used. But something happened, which ended the Web 2.0 era, and Web 3.0 became the new kid in the town.
Web 3.0
When we hear the term Web 3.0, most of us think about decentralized web, Bitcoin, NFTs, and blockchain. But in my opinion those technologies are unrelated to the Web. The Web was, and still is, a decentralized system. Yes, it is controlled by few major corporations. But nothing forbids me to buy a server, put it in a rack at my home, and plug in into the internet in order to serve my blog from it.
For me, Web 3.0 means the birth of the semantic web. Somewhere around the peak popularity of Facebook, the Web stopped being about webpages, and started to become more about things. When I search for @skwee357, I don’t want to find webpages that contain this obscure phrase/word. I want to find a person behind this handle (which is me). When I search for “Fight club”, I want to find the movie by David Fincher. The search term, “how to make pancakes”, should ideally yield a set of recipe results for pancakes.
Web 3.0 is about things. It’s no longer about webpages and content. It’s about people, movies, recipes, tutorials, places, events, books. And the current state of things with Web 3.0—has one drawback.
The birth of the semantic web
As I’ve noted earlier, during the Web 2.0 era, HTML got some new elements that aimed to make it more semantic. Here is a list of some of them. But have you ever wondered what’s the different between a <div> element and an <article> element? <span> vs <div> is a simple answer. The first does not create a new block, and can be incorporated inside a sentence without breaking it. But most of the other elements, such as <article> or <header>, do not have different behavior than say a <div>.
They do serve one major role—to help make the web more semantic. With the increased usage of the Web, came increased production of web content. And the latter created a demand for increased searching and indexing capabilities. And these semantic HTML elements—help search engines to classify your content. When a crawler sees an <article> element—it knows that the text, inside of it, is indeed an article. Compare that to a generic <div> which does not provide any information about the nature of it’s content. It could be an article, but also could be a table of contents.
Have you noticed how Google sometimes provide a snippet from Wikipedia, or recommend you a video from YouTube or Vimeo? How does Google, or any other search engine, knows to classify between a general section on your web page, and the content of the blog post? Probably by looking at the <article> HTML element. But there is more. How does a search engine know that “Brad Pitt” is an actor, “Fight Club” is a movie, and “1984” is a novel?
Semantic semi standards
Like with any new and established standard, someone first created a semi-standard. And this is what happening to Web 3.0 now. I believe that Facebook was the first to create the og meta attributes to classify content. A webpage with correct <meta> tags with og attributes—will provide semantic information to those who parse the og meta attributes. One could provide information such as site name, description, associated image, etc. The og attributes are responsible for content sharing. When you post a link to Facebook or LinkedIn, those platforms query the og attributes in order to extract the title of the webpage, description, as well as cover image.
But meta attributes are limiting. And so other formats were created. I believe the first among them was RDF—Resource Description Framework. RDF never gain much popularity, and was served as a foundation to newer semi-standards such as JSON-LD and Microdata, which I mentioned earlier when I wrote about HTML5. Those two formats took a different approach.
Microdata
Microdata was targeting to enhance existing HTML elements. By using Microdata, one can provide a set of special attribute to any HTML element. Combining with a set of predefined schemas, such as event, product, and review—one can provide additional context to crawlers about the nature of the content on a webpage. A geolocation with Microdata will look like this:
<div itemprop="geo" itemscope itemtype="https://schema.org/GeoCoordinates">
<span itemprop="latitude">52.48</span>
<span itemprop="longitude">-1.89</span>
</div>Interestingly enough, according to MDN, Microdata support was removed from Firefox 49. According to Wikipedia—no major browser support the Microdata DOM API. Google developers portal tells us that Google, still, does care, and parse, Microdata.
Microformats
Somewhere around the time Microdata became a thing, another semi-standard, that’s called Microformats—was created. Microformats took a similar approach to Microdata, but instead of relying on a good set of schemas to classify things (like the above event, product, or review I’ve mentioned), it went on to define custom CSS classes. So a geolocation would be marked as:
<span class="h-geo">
<span class="p-latitude">52.48</span>,
<span class="p-longitude">-1.89</span>
</span>This approach created some problems. For starters, there was no schema definition for thing. A crawler would have to implement all the h-* and corresponding p-* classes. Extending Microformats was practically impossible. In addition to that, the usage of CSS classes to classify content semantically—feels wrong.
JSON-LD
Lastly, we need to talk about JSON-LD. JSON-LD is also a semantic web format. But instead of trying to build upon existing convention—like HTML element attributes, or CSS classes—JSON-LD relies on encoding your entire semantic information, in a script tag. Here’s how it looks for the homepage of my blog:
<script type="application/ld+json">
{
"@context":"https://schema.org",
"@type":"Blog",
"@id":"https://www.yieldcode.blog",
"name":"yield code();",
"description":"Thoughts and stories on programming, the industry, and technology written by a software engineer",
"author":{
"@type":"Person",
"@id":"https://www.kudmitry.com/",
"name":"Dmitry Kudryavtsev",
"sameAs":["https://www.kudmitry.com/","https://linkedin.com/in/kudmitry","http://github.com/skwee357","http://twitter.com/skwee357"],
"image":{
"@type":"ImageObject",
"url":"https://res.cloudinary.com/dvp7olno1/image/upload/v1673035861/yieldcode/cover_eacuil.jpg",
"height":"150",
"width":"150"
}
},
"keywords":["programming","software industry","software engineering","tutorials","programming consulting","tech lead","architect"]
}
</script>JSON-LD is one of the most popular semantic web formats, and it is the one recommended by Google. RDF and Microdata never became popular. Microformats has a small community among IndieWeb people, but it’s hardly a specification. It’s a gross hijack of CSS classes—that were created to style the HTML elements—not provide semantic information.
Making Web 3.0 great
HTML is an established format and specification. By looking at this webpage, you already have most of the semantic information you need. It makes no sense to duplicate the same semantic information inside a JSON in the HTML <header> tag, for the sake of crawlers. This creates unnecessary duplication, which in turn makes the webpage heavier.
However, with the rise of Web 3.0 and the content era, we have to help crawlers understand our content better. The web needs to become cleaner for machines, so it will become cleaner for humans. If we introduce HTML elements such as tag, author, recipe, and others—we can create a better web for machines, which will help to create a better web for us—humans.
Call to action
Web Hypertext Application Technology Working Group, also known as WHATWG, is a community of people interested in evolving the HTML. About a month ago, I’ve created a proposal at WHATWG Github: Elements for a more semantic web.
The web is built on open formats. The evolution of HTML is needed in order to keep up with the changing nature of the Web. I hope I was able to convince you that we need to move HTML forward, and adapt it to the new reality of the Web 3.0—the semantic web. Failing to do so, will force us to use formats that were created, and controlled, by corporations—better built to serve their needs, rather than ours. In addition to that, by failing to provide semantic information to crawlers, we will either have to place our hope in the hands of AI classification tools (which are far from optimal), or worse—drown in a sea of search results that make no sense.
If I did convince you, then please go to my proposal and show your support. Together we will move HTML to its next level.