Web app localization. In Rust.
Doing localization is complicated. Many websites, even big ones, get it wrong. Let me share how I did it. In Rust of course.
Localization, often times stylized as l10n, is a process of adapting your website or web application to meet the requirements of specific target market (known as “locale”).
It’s one of the 3 processes of going global, which include:
- Translation (
t9n)—the process of translating the content to a target language - Localization (
i10n)—the process that I described above - Internationalization (
i18n)-the process of adapting numbers, prices, dates, etc—to a target market/locale
Today, I want to talk about localization, why I think some websites do it wrong, and how I did it in my recent side project: JustFax Online. Are you ready? Bon voyage!
Oh, Rust code included 🦀!
Step one—understanding your users
I want to start with the obvious—how do you understand where your users are coming from?
What not to do
Many websites, Google and PayPal among them, are doing it wrong. For some reason, they are obsessed with GeoIP. But let me tell you a story.
For the past 6 months, I’m nomading in Central America. People in Central America—speak Spanish. I, however, hablo poco español (Spanish for “I don’t speak too much Spanish”). But both Google and PayPal (and I believe there are many other websites), insists on serving me their websites in Spanish.
With PayPal, it’s easy, they have a language switcher at the bottom, so I waste 2 seconds of my life every time I need to pay with PayPal. Google, on the other hand, is more complicated. The other day, I was given access to a Google Document through my non Google account, and after opening it, I saw that it was entirely on Spanish. I wasn’t able to find a way to revert it back to English. Luckily I know the Google Docs interface well enough that I was able to manage it.
The reason I got served the Spanish version of their websites—is because my IP is originated from a Spanish-speaking country, in my case Mexico. Switching on VPN to a different country, with different language, would serve their website in that particular language.
I understand the desire of whoever made this decision to have a good user experience, but in my opinion it’s horrible, and there is a better way to do it.
Meet the Accept-Language header
Accept-Language is a standard HTTP header that every browser sends.
Instead of relying on GeoIP, the browser tells the server what languages I prefer, based on the settings of my device.
My macOS is in English, therefor my Accept-Language looks like this: Accept-Language: en-US,en;q=0.5.
Yes, Accept-Language can even have multiple languages.
Every OS has a setting to set the preferred languages, and countries, and desktop applications seem to respect that.
But web being web, prefers to use fancy GeoIP methods to wrongly guess my language.
But enough talking, let’s see how we can extract Accept-Language header with Rust and axum framework.
If you are interested to read my take on Rust and axum for web development, make sure to check my last blog post Building a web app in Rust.
I always prefer to use TypedHeader.
While writing this article, I found out that axum 0.7 was released.
And it brings a breaking change to the header module.
TypedHeader is no longer part of axum, and was moved to axum-extra.
You can read more about it in the changelog.
I haven’t upgraded to axum 0.7 yet, therefor the rest of this article relies on axum 0.6.x.
TypedHeader allows us to extract request headers in a type-safe way.
axum has many headers defined that you can use with TypedHeader, but unfortunately, Accept-Language is not one of them.
So I had to write my own.
It’s not that hard.
Defining the struct for accepted language
First, we need to write a struct that will hold a pair of language identifier and quality values, essentially holding a string like this: en-US;q=0.5.
Let me dump the code first, and then we will go over it.
#[derive(Debug, Error)]
pub enum AcceptLanguageError {
#[error("Invalid value")]
InvalidValue,
}
pub struct AcceptedLanguage {
pub value: String,
pub quality: f32,
}
impl Eq for AcceptedLanguage {}
impl PartialEq for AcceptedLanguage {
fn eq(&self, other: &Self) -> bool {
self.quality == other.quality && self.value.eq(&other.value)
}
}
impl PartialOrd for AcceptedLanguage {
fn partial_cmp(&self, other: &Self) -> Option<std::cmp::Ordering> {
Some(self.cmp(other))
}
}
impl Ord for AcceptedLanguage {
fn cmp(&self, other: &Self) -> std::cmp::Ordering {
if self.quality > other.quality {
std::cmp::Ordering::Greater
} else if self.quality < other.quality {
std::cmp::Ordering::Less
} else {
std::cmp::Ordering::Equal
}
}
}It’s a very simple struct that holds a string and a float, and supports comparison and ordering (based on quality value).
Next, we need a way to create such structs.
Since the most common scenario is creating them from a string, I’ve opted for implementing FromStr trait.
impl FromStr for AcceptedLanguage {
type Err = AcceptLanguageError;
fn from_str(s: &str) -> Result<Self, Self::Err> {
let mut value = s.trim().split(';');
let (value, quality) = (value.next(), value.next());
let Some(value) = value else {
return Err(AcceptLanguageError::InvalidValue);
};
if value.is_empty() {
return Err(AcceptLanguageError::InvalidValue);
}
let quality = if let Some(quality) = quality.and_then(|q| q.strip_prefix("q=")) {
quality.parse::<f32>().unwrap_or(0.0)
} else {
1.0
};
Ok(AcceptedLanguage {
value: value.to_string(),
quality,
})
}
}Here, again, we don’t have anything special.
We take a string such as en;q=0.5, and break it to its value and quality components.
Keep in mind that quality is optional, and default to 1 if not specified.
Lastly, in order for TypedHeader to extract our custom header, we have to implement the Header trait.
pub struct AcceptLanguage(pub Vec<AcceptedLanguage>);
impl Header for AcceptLanguage {
fn name() -> &'static axum::http::HeaderName {
&header::ACCEPT_LANGUAGE
}
fn decode<'i, I>(values: &mut I) -> Result<Self, axum::headers::Error>
where
Self: Sized,
I: Iterator<Item = &'i axum::http::HeaderValue>,
{
let value = values.next().ok_or_else(axum::headers::Error::invalid)?;
let str = value.to_str().expect("Accept-Language must be a string");
let mut languages = str
.split(',')
.map(AcceptedLanguage::from_str)
.collect::<Result<Vec<AcceptedLanguage>, AcceptLanguageError>>()
.map_err(|_| axum::headers::Error::invalid())?;
languages.sort();
Ok(AcceptLanguage(languages))
}
fn encode<E: Extend<axum::http::HeaderValue>>(&self, values: &mut E) {
let val = self
.0
.iter()
.map(|l| format!("{};q={}", l.value, l.quality))
.join(",");
let val = HeaderValue::from_str(&val).expect("Accept-Language must be valid");
values.extend(std::iter::once(val))
}
}As I said, Accept-Header is an array of language identifiers and quality values, separated by comma.
Therefor, I break the string by the comma character, and map it to my custom AcceptedLanguage struct.
Extracting preferred language
Next step, is to create a middleware that will extract the preferred language of the user.
The purpose of this middleware, is to look at the Accept-Language header, and compare the values to our supported languages.
JustFax is offered in English, German, and French, and their all defined in a toml config:
supported_languages = ["en", "de", "fr"]You can have a better user experience if you decide to target different countries, differently.
For example American English (en-US), is different from British English (en-GB).
I didn’t go that deep, and opted to offering American English to all my English-speaking audience.
Apologies for that.
The middleware is not that hard:
#[derive(Clone)]
pub struct PreferredLanguage(pub Option<LanguageIdentifier>);
pub async fn extract_preferred_language<B>(
request: Request<B>,
next: Next<B>,
) -> impl IntoResponse {
let config = get_config();
let span = tracing::span!(Level::TRACE, "preferred language extraction");
let _enter = span.enter();
let (mut parts, body) = request.into_parts();
let preferred_lang: Option<LanguageIdentifier> =
if let Ok(TypedHeader(accept)) = parts.extract::<TypedHeader<AcceptLanguage>>().await {
accept
.0
.iter()
.filter_map(|lang| lang.value.parse::<LanguageIdentifier>().ok())
.filter(|lang| config.locale.supported_languages.contains(lang))
.collect::<Vec<LanguageIdentifier>>()
.first()
.map(|lang| lang.to_owned())
} else {
None
};
tracing::event!(
Level::TRACE,
"extracted preferred language: {:?}",
preferred_lang
);
let mut request = Request::from_parts(parts, body);
request
.extensions_mut()
.insert(PreferredLanguage(preferred_lang));
next.run(request).await
}I use another library, called unic_langid that is able to parse strings such as en-US into their respective language, region, script and variants.
It makes it easier to validate the locale strings, as well as comparing them.
The middleware takes the Accept-Language that we’ve created earlier, map each language to LanguageIdentifier, and filter out the ones that are not supported.
If you look again at the Accept-Language header that we’ve implemented, it spits out a sorted array of languages based on quality.
Therefore, we are guaranteed to pick the most preferred language that both the user, and our website, support.
Once we identified the preferred language, we put it in a axum extension, for future handlers to extract.
Keep in mind that it can be None for cases where none of the languages in the Accept-Langauge header are supported by us (or the header is empty/invalid).
In that case, I default to English as this is the main language of my application.
Step two—serving localized pages
We now have a way to extract user’s preferred language, using cutting-edge technology GeoIP Accept-Language header.
The next step, is to serve the content in each language.
Defining URL scheme
There are 4 main ways to define your multilingual URLs. Using a country specific domain such as example.de; using a subdomain such as de.example.com; using a subdirectory such as example.com/de; and lastly, using query parameter such as example.com?lang=de.
Domains are expensive, so the first option goes to trash. Subdomains could be a good option, but I didn’t want to mess with DNS settings. Query parameters are bad option, and are not recommended by Google. I opted for using subdirectories.
It’s funny, now I see it. On the above webpage by Google, they have a strong red warning that says: Don’t use IP analysis to adapt your content. But that’s what they are doing. Side effects of being a big-corp.
After deciding on the URL scheme, you need to decide what do you do with the root URL. Some websites leave the root URL to be the default language (for example, English). Others, might show a language chooser on the root URL (I don’t like that approach). I opted for a different approach: redirecting the root URL to a language specific URL.
So when a user navigates to justfaxonline.com/availability, he/she will be redirected (we will cover the redirection process in a bit), to a language specific subdomain, for example: justfaxonline.com/de/availability.
In order to achieve this, I had to do some dancing with axum router.
I first needed to create the root routes:
fn make_root_router() -> Router<AppContext> {
Router::new()
.route("/", get(redirect_handler))
.route("/availability", get(redirect_handler))
.[some more routes]
.layer(middleware::from_fn(middlewares::extract_preferred_language))
}This router covers all the GET pages, and instead of serving the HTML, it calls a redirect_handler (hang on, we will get to it), which redirects to the appropriate locale subdomain.
Then, I had to create the actual router:
let main_router = web::router()
.merge(content::router())
.layer(middleware::from_fn(middlewares::extract_preferred_language));
for lang in &config.locale.supported_languages {
router = router.nest(
&format!("/{}", lang.to_string().to_lowercase()),
main_router
.clone()
.layer(Extension(DetectedLanguage(lang.clone()))),
);
}This router simply loops through all the supported languages from the config file, and creates a subdirectory for them. In addition to that, the main router also gets the preferred user language, as well as the detected language (which is the actual language of this particular route). We need them both in order to properly redirect the user, and provide a nice UX.
Lastly, we need to talk about user experience.
First time users should be redirected based on their Accept-Langauge header.
However, what if my computer is in Spanish, but when visiting JustFax Online, I prefer to use English?
Meet: the cookie.
After the raise of SPAs (single page applications), it seems like people forgot about the existence of cookies.
But cookies are very handy to store non-sensitive user information.
They are being sent with each request, event if the request is made with Ajax.
You don’t need any specific JavaScript code to send them, unlike LocalStorage.
On my website, I have a language picker at the bottom that allows you to switch language.
Once you click it, there is some JavaScript on the client side that is used to set/overwrite the cookie, and then refresh the webpage.
On the backend, I read this cookie and do the proper redirection.
I’ll spare you the JavaScript code, but here is the backend code for redirect_handler:
async fn redirect_handler(
Extension(PreferredLanguage(preferred_langauge)): Extension<PreferredLanguage>,
OriginalUri(uri): OriginalUri,
jar: CookieJar,
) -> impl IntoResponse {
let config = get_config();
let selected_language = match jar.get("lang") {
None => None,
Some(cookie) => cookie
.value()
.parse::<LanguageIdentifier>()
.map(Some)
.unwrap_or(None),
};
let mut lang = selected_language.as_ref().unwrap_or_else(|| {
preferred_langauge
.as_ref()
.unwrap_or(&config.locale.default_language)
});
if !config
.locale
.supported_languages
.iter()
.any(|item| item.matches(&lang, false, false))
{
lang = &config.locale.default_language;
}
let url = get_url(uri.path(), lang);
event!(Level::TRACE, "redirecting: {}", url);
Redirect::temporary(&url)
}It’s a simple code that reads from the CookieJar; if no cookie with the language exists, it reads the language from the preferred language (which comes from Accept-Language header); and if it doesn’t exist, or none of them are supported, it falls back to the default language.
Here you can also see the usage of unic_langid::LanguageIdentifier::matches function.
This function is able to compare two languages, and based on the seconds and third arguments, to treat them like range.
This allows comparing en and en-US easier.
But I don’t like JavaScript!, I hear you say.
And I’m with you. JavaScript is overused nowadays, and usually for bad purposes like annoying popup windows.
However, I try to keep my JavaScript code to a minimum. In fact, aside from htmx and some event handlers, JustFax Online is mostly JavaScript free.
If you browse the web with disabled JavaScript, you will lose functionality. I’d like to have you as a customer, but I also care about a nice user experience.
So I always need to balance those to aspects.
A touch of UX
Some websites put the language switcher on the top; others at the bottom. And some, hide it in obscure places, never to be found again. I appreciate a UI that puts me, the user, in the center. This is why I added a nice touch to the UI of JustFax.
When your preferred language (the one that comes from the Accept-Header), and your detected language (the actual subdomain language)—differ—I show you a nice, unintrusive popup:
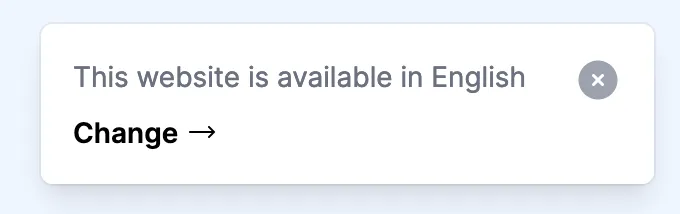
You can either revert to your preferred language, or hide this popup, never to be shown again (for the next 30 days).
Step three—actual localization
I hope you are not tired, but we need to talk about how to actually localize your web pages.
There exist a multitude of tools and frameworks to do so.
The lamest one look at a key, and it’s associated string.
So for example you could have a en.toml with the content of:
features-title = FeaturesAnd a de.toml with the content of:
features-title = FunktionenAnd a magic t() function in your templates, that will accept a key, and output its value.
This is a lousy solution, if you aim for perfection (like I do). Language is way more than just a collection of words. One obvious example, is when enumerating things. In English, you would say “Close one tab” and “Close n tabs” for any number of tabs other than one. However, in many Slavic languages, you would use a different imperative for the word “tabs”. In Polish for example, you would say “Zamknij kartę” for one tab; “Zamknij {$tabCount} karty” for few tabs (2, 3, and 4); and “Zamknij {$tabCount} kart” for many tabs (5, 6, and on). In addition to imperatives, you might have different variants of translation based on gender, how lower/upper case is handled, etc. So in short, languages are fun!
There exists a tool made by GNU called gettext.
It’s very robust tool for l10n.
The main feature of it, is that you will use an agreed function name, usually _(), and the parameter of this function would be an English phrase: _("Hello World").
You’d then run the gettext utility over your source code, and it will generate a .po file to which it will export all the strings in your source code.
By using POEdit GUI application, you will be able to translate those files, or give them to a translator.
It’s a very robust tool that exists from 1990.
It’s written in C, and there are Rust crates that interface with it.
It doesn’t pollute your code with obscure keys like feature-title.
I, however, dislike it due to the fact that it needs to go over my source code, which means I need to have another pre-deploy task to perform.
Moreover, because the actual phrase is your key, when you find a typo, good luck fixing all your translations.
Luckily, I was able to find Project Fluent which is maintained by Mozilla, and is used in Firefox.
It addresses many of the issues with gettext, and luckily for me, has a Rust implementation.
The implementation is very raw though, and requires some juggling to make it work.
But, as you already understood, I’m very lucky and there is another crate, called fluent-templates, which makes working with fluent-rs way easier.
More luck on my side, it has a built-in implementation of the t() function for the tera templating engine that I use.
Inside a tera template, I would call it like this:
<p>{{ t(key="hello-world", lang=LANG) }}</p>LANG is a global variable defined in the tera context, based on the detected language of the route.
This article is already too long, so feel free to check fluent-templates documentation.
It’s pretty straightforward.
Conclusion
Things like l10n and i18n are hard to get right.
Even giants like Google mess up sometimes.
I hope in this article I was able to cover the basic building blocks you would need for your own localized web applications in Rust.
Bear in mind that I didn’t even touch things like numbers, currencies and dates, which have their own caveats.
Maybe I’ll do one day in the future.